Hoe bouw je een CI/CD pipeline voor embedded firmware?
Van compilatie tot release: wat er in een embedded CI/CD pipeline hoort, waarom elk onderdeel er is, en hoe je het concreet implementeert met GitHub Actions.
Praktische handleiding voor het opzetten van een volledige CI/CD pipeline voor embedded firmware, met werkende voorbeelden uit een dual-microcontroller IoT-platform.
Waarom CI/CD voor embedded anders is
In webdevelopment is CI/CD min of meer een opgelost probleem. Je draait je tests in een container, deployt naar een server, en als het misgaat draai je terug. De tooling is volwassen, de patronen zijn gestandaardiseerd, en je draait alles op dezelfde x86-architectuur als je productieomgeving.
In embedded is bijna niets daarvan waar:
- Je compileert voor een andere architectuur dan je CI-server. Een ESP32 draait op Xtensa of RISC-V, een STM32 op ARM Cortex-M. De compiler, de linker, de standaardbibliotheek: alles is anders.
- Je binair moet in het flashgeheugen passen. Geen virtueel geheugen, geen swap, geen dynamische linking. Als je binary 1 byte te groot is voor de partitie, doet het device het niet. En je merkt het pas als je het probeert te flashen.
- Je kunt niet zomaar "terugdraaien". Een firmware update die een device bricked is niet op te lossen met
git revert. Iemand moet fysiek naar het device toe. - Er is geen standaard testrunner. Unity, CMock, GoogleTest: elke embedded shop gebruikt iets anders. En de meeste tests die er echt toe doen (timing, interrupts, hardwareinteractie) kun je niet op een x86-host draaien.
Het gevolg: een embedded CI/CD pipeline heeft meer stappen, meer toolchains, en meer risicobeheersing nodig dan een webproject. Maar het principe is hetzelfde: elke commit moet automatisch gevalideerd worden voordat hij in productie belandt.
Dit artikel beschrijft de lagen van een embedded CI/CD pipeline, van compilatie tot release. Elk onderdeel wordt geïllustreerd met concrete voorbeelden uit een werkend dual-microcontroller platform (ESP32-S3 + STM32F767), maar de principes zijn toepasbaar op elk embedded systeem.
De lagen van een embedded pipeline
Deze pipeline is opgebouwd uit zeven lagen. Elke laag vangt een andere klasse fouten, van snel en goedkoop (compilatie) naar traag en duur (hardwaretests). Het precieze aantal varieert per project, maar de volgorde is vrijwel altijd dezelfde:

* In de praktijk draaien lagen 1–4 als losse GitHub Actions workflows die parallel triggeren op dezelfde PR. De lineaire weergave toont de logische volgorde van gates, niet de exacte uitvoeringsstructuur.
| Laag | Wat het vangt | Doorlooptijd | Runner |
|---|---|---|---|
| Build | Compileerfouten, linkerfouten, ontbrekende symbolen | 2–5 min | Cloud |
| Size check | Binary past niet in flash, regressie in geheugengebruik | Seconden | Cloud |
| Static analysis | Bugs zonder te compileren: null pointers, buffer overflows, naamgevingsfouten | 3–8 min | Cloud |
| Unit tests | Logicafouten in platform-onafhankelijke code | 1–2 min | Cloud |
| Hardware tests | Integratiefouten, timing, hardware-interactie | 5–15 min | Self-hosted |
| Security scan | Gelekte secrets, API-keys, private keys in de repository | 30 sec | Cloud |
| Release | Signing, upload, notificatie | 3–5 min | Cloud |
Niet elke laag draait bij elke trigger. Op feature branches draaien build, size check, static analysis, unit tests, en secrets scan. HIL-tests zijn te traag en hardwaregebonden voor elke push, die draaien alleen bij een PR naar master. De release-pipeline triggert uitsluitend op version tags en vereist handmatige goedkeuring.
CI/CD platform keuze
Dit artikel gebruikt GitHub Actions, maar de lagen hierboven zijn platform-onafhankelijk. Welk platform past hangt af van één vraag: mag code de eigen infrastructuur verlaten?
De sweet spot voor de meeste freelance- en startup-embedded projecten. Lage overhead, uitstekende toolchain-support, gratis voor publieke repositories. Cloud voor build en analyse, self-hosted runner voor HIL.
Sterker zodra compliance een harde eis stelt: niets naar de cloud. Self-hosted geeft volledige controle over runner, artifact registry, en secrets. De syntax verschilt, maar elke laag is direct vertaalbaar.
De legacy keuze bij grotere industriële klanten. Maximaal flexibel, maar hoge onderhoudslast. Als de klant het al heeft, bouw je er gewoon in — de concepten zijn direct vertaalbaar naar Jenkins stages.
Voor airgap-omgevingen: alles op eigen hardware, inclusief Git-server, CI-runner, en container registry. Vrijwel dezelfde YAML-syntax als andere moderne CI-tools.
Welk platform past bij jouw situatie?
Code mag de infrastructuur niet verlaten → GitLab self-hosted of Jenkins
Je hebt al een DevOps-platform → integreer daarmee (GitLab, Azure DevOps, Jenkins)
Nieuw project, geen restricties → GitHub Actions
Airgap of volledig self-hosted → Gitea + Woodpecker
De pipeline-code in dit artikel is GitHub Actions, maar als je op een ander platform zit: de YAML-structuur verschilt, de principes niet.
Laag 1: Build, compileer voor de juiste architectuur
De build-stap lijkt triviaal, maar heeft in embedded drie uitdagingen die webprojecten niet kennen.
Cross-compilatie. Je CI-server draait Linux x86_64, maar je target is ARM Cortex-M7 of Xtensa LX7. Je hebt de juiste toolchain nodig, en die moet exact dezelfde versie zijn als op je ontwikkelmachine. Een subtiel verschil in compiler-optimalisatie kan het verschil zijn tussen werkende en falende firmware.In de praktijk betekent dit: pin je toolchain-versie, cache het resultaat, en verifieer de versie bij elke run:
env:
ARM_TOOLCHAIN_VERSION: "14.3.rel1"
steps:
- name: Cache ARM GCC toolchain
uses: actions/cache@v4
with:
path: /opt/arm-toolchain
key: arm-none-eabi-gcc-${{ env.ARM_TOOLCHAIN_VERSION }}-linux-x86_64
- name: Download if not cached
if: steps.cache-arm-gcc.outputs.cache-hit != 'true'
run: |
curl -fsSL "$ARM_TOOLCHAIN_URL" -o /tmp/arm-gcc.tar.xz
tar -xf /tmp/arm-gcc.tar.xz -C /opt/arm-toolchain --strip-components=1
Waarom niet apt-get install gcc-arm-none-eabi? Omdat de apt-versie achterloopt, verschilt per Ubuntu-release, en niet dezelfde codegen oplevert als de officiële ARM-release. Voor embedded firmware wil je bit-voor-bit reproduceerbaarheid.
- name: Build ESP32 firmware
uses: espressif/esp-idf-ci-action@v1
with:
esp_idf_version: v5.5
target: esp32s3
path: ESP32
De image bevat de volledige ESP-IDF toolchain, inclusief de Xtensa compiler, Python-dependencies, en build-tools. De build draait in de container, maar de broncode en ccache-directory worden via volume mounts gedeeld met de host.
Ccache voor snelheid. Een volledige ESP-IDF build duurt 8–12 minuten. Met ccache (compiler cache) daalt dat naar 2–3 minuten voor incrementele wijzigingen. De truc is om de ccache-directory te persisteren tussen CI-runs:
- name: Cache ccache
uses: actions/cache@v4
with:
path: .ccache
key: ccache-esp32-${{ github.sha }}
restore-keys: ccache-esp32-
Door github.sha als key te gebruiken en ccache-esp32- als fallback, krijg je altijd de meest recente cache, ook als de exacte SHA niet eerder is gebouwd.
Laag 2: Size check, past het in flash?
Dit is een stap die in webdevelopment niet bestaat. Een microcontroller heeft een vast flashgeheugen, opgedeeld in partities. Als je binary groter is dan de partitie, start het device niet op. En het ergste: de compiler geeft geen foutmelding. De build slaagt gewoon. Je merkt het pas als je flasht.
De oplossing: valideer de binary-grootte als onderdeel van de build, en faal de pipeline als de limiet wordt overschreden:
- name: Validate firmware flash size
run: |
python3 scripts/check_flash_sizes.py esp32 \
ESP32/build/iot_gateway.bin \
--partition-csv ESP32/partitions_ota.csv \
--json-output esp32-size-metrics.json
Het script leest de partitietabel, vergelijkt de binary-grootte met de beschikbare ruimte, en faalt als de limiet wordt overschreden. De metrics worden als JSON opgeslagen voor de volgende stap.
Size delta op pull requests. De absolute grootte is nuttig, maar de trend is informatiever. Bij elke PR wordt een comment gepost met de grootte van de PR-branch ten opzichte van develop: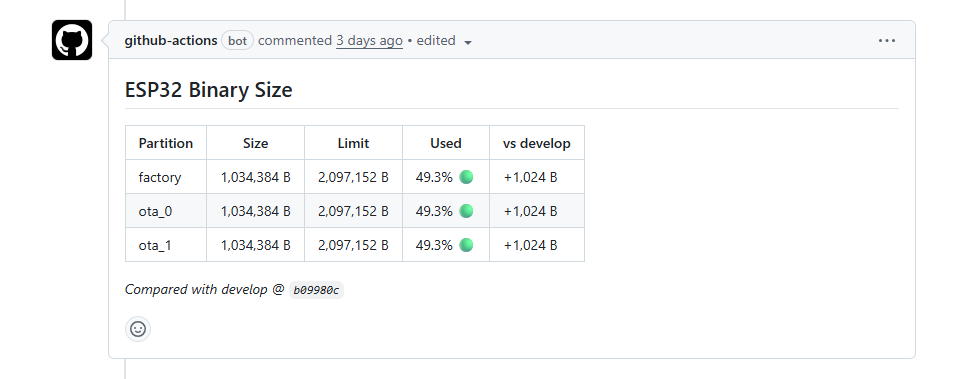
Het stoplichtmodel (groen, geel, rood) maakt in één oogopslag duidelijk of er actie nodig is. Geel (boven 90%) is een waarschuwing. Rood (boven de limiet) blokkeert de merge.
Dit is een van die stappen die weinig moeite kost om op te zetten, maar veel ellende voorkomt. Zonder size tracking groeit je binary geleidelijk, en op een dag past hij niet meer. Met size tracking zie je elke regressie bij de pull request die hem veroorzaakt.
Laag 3: Static analysis, bugs vinden zonder te draaien
Static analysis is in embedded minstens zo waardevol als in andere domeinen, misschien zelfs meer. De consequenties van een null pointer dereference of buffer overflow zijn op een microcontroller ernstiger: geen segfault met een nette foutmelding, maar een hard fault die het device onmiddellijk reset, of erger, stilletjes corrupte data produceert.
Twee tools dekken het meeste af:
Cppcheck voor semantische analyse: ongeïnitialiseerde variabelen, ongebruikte functies, verdachte pointer-arithmetic. Het is conservatief (weinig false positives) en snel. Clang-tidy voor diepere analyse: het gebruikt de complete AST (Abstract Syntax Tree) en kan bugs vinden die cppcheck mist, zoals verdachtesizeof-expressies, potentieel onveilige API-aanroepen, en naamgevingsconventies.
Beide tools hebben de compile_commands.json nodig die de build-stap genereert. Daarom draait static analysis als een aparte job die de build-artifacts downloadt:
analyze:
needs: build
steps:
- name: Download build artifacts
uses: actions/download-artifact@v4
with:
name: esp32-iot_gateway-${{ needs.build.outputs.sha-short }}
path: ESP32/build
- name: Run static analysis
run: bash scripts/lint.sh esp32
Het lint-script draait beide tools en telt de fouten. Elke fout blokkeert de merge. Dat klinkt streng, maar het alternatief, een groeiende lijst "bekende warnings" die niemand meer leest, is erger.
Naamgevingsconventies afdwingen. Clang-tidy kan ook codestijl valideren. In een embedded codebase met gedeelde headers tussen platformen is consistente naamgeving niet cosmetisch maar functioneel:
# .clang-tidy (fragment)
Checks: 'readability-identifier-naming'
CheckOptions:
readability-identifier-naming.FunctionCase: lower_case
readability-identifier-naming.VariableCase: lower_case
readability-identifier-naming.MacroDefinitionCase: UPPER_CASE
readability-identifier-naming.TypedefSuffix: _t
Een functie die getStatus() heet in een codebase die get_status() verwacht, wordt gevangen voordat een reviewer het hoeft op te merken.
AI-gebaseerde RTOS review
Static analysis tools zijn goed in patroonherkenning, maar missen vaak de semantische context die nodig is om concurrency-bugs in FreeRTOS-code te vinden. Een mutex die in de verkeerde volgorde wordt vergrendeld, een ISR die een blocking API aanroept, een taak die zonder timeout op een semaphore wacht: dit zijn bugs die pas optreden onder specifieke timing-condities en die statische tools niet betrouwbaar detecteren.
Als aanvulling draait er een Claude-gebaseerde review-agent die gewijzigde C-bestanden analyseert op RTOS-specifieke kwetsbaarheden:
rtos-review:
steps:
- name: Run RTOS vulnerability review
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
RTOS_REVIEW_MODEL: claude-haiku-4-5-20251001
run: |
python tools/rtos_review_agent.py ${{ steps.prereqs.outputs.files }} \
> /tmp/rtos_review.json
De agent werkt in drie passen: een initiële analyse, een zelfverificatie (om false positives te elimineren), en een deterministische evidence grounding die controleert of de geclaimde identifiers daadwerkelijk in de code staan op de aangegeven regelnummers.
Wat het in de praktijk vindt. Een run op de dashboard-module leverde twee klassen bevindingen op:
De WRAPPER_BYPASS-bevindingen (regels 750, 830, 843, 873, 884) zijn echte problemen. De rest van de codebase gebruikt consequent os_mutex_take/os_mutex_give, maar drie functies (dashboard_broadcast, dashboard_broadcast_json, dashboard_disconnect_all) roepen FreeRTOS direct aan. Geen correctheidsbug vandaag, want os_mutex_take wrrapt xSemaphoreTake één-op-één, maar het doorbreekt de abstractielaag en is een onderhoudsprobleem.
De SHARED_STATE-bevinding op regel 358 is ook een echte data race: state.stats.messages_received++ is een onbeschermde read-modify-write. Op de ESP32 (Xtensa) zijn 32-bit loads en stores atomair, maar ++ is dat niet. Twee gelijktijdige WebSocket-handlers kunnen increments verliezen. In de praktijk gaat het alleen om een statistiekenteller, geen veiligheidsimpact, maar de agent heeft gelijk dat het technisch een race is.
De output wordt als markdown samenvatting in de GitHub Actions job summary geschreven, met severity, confidence, en een beschrijving van de bug flow. Alleen CRITICAL findings met HIGH confidence blokkeren de build. De rest is informatief.
Een belangrijk ontwerpdetail: de agent skipt graceful als de API-key niet geconfigureerd is (bijvoorbeeld bij fork PRs). Geen harde failure, alleen een notice in de log. Dit voorkomt dat externe contributors worden geblokkeerd door een ontbrekende secret.
De RTOS review agent is één voorbeeld van een bredere aanpak: agentic code review in CI, waarbij een AI-model niet alleen patronen herkent maar redenering toepast op codewijzigingen. Hoe de agent context opbouwt, valideert, en false positives elimineert, is uitgebreid genoeg voor een apart artikel, dat komt eraan.
Laag 4: Unit tests, logica valideren op de host
De gedeelde code (parsers, protocoldefinities, utility-functies) kan getest worden zonder embedded hardware. Tests compileren voor x86-64 met een gewone GCC, en draaien direct op de CI-runner:
- name: Configure host test build
run: |
cmake -S tests -B tests/build \
-G Ninja \
-DCMAKE_BUILD_TYPE=Debug \
-DENABLE_COVERAGE=ON
- name: Run tests
run: ctest --output-on-failure --parallel "$(nproc)"
Het testframework is Unity (een minimalistisch C test framework) met CMock voor mock-generatie. Beide worden als git-submodules meegeleverd, zodat de testomgeving volledig reproduceerbaar is.
Code coverage met een threshold. Coverage meten is eenvoudig metlcov. De output filteren op alleen de relevante bronbestanden (en niet de gegenereerde mocks of vendor-code) is de truc:
- name: Extract coverage for common sources only
run: |
lcov --extract coverage_raw.info "*/common/src/*" \
--output-file coverage.info
- name: Enforce coverage threshold (60%)
run: |
# Parse lcov summary, fail if line coverage < 60%
De threshold van 60% is bewust niet hoog. De meest kritische code (interrupt handlers, DMA-configuratie, hardware-initialisatie) is per definitie niet host-testbaar. Een hoge threshold zou je dwingen om triviale wrappers te testen puur voor de coverage-score. De 60% dekt de logica die wél zinvol op de host kan draaien: parsers, state machines, utility-functies.
Laag 5: Hardware-in-the-Loop tests
Dit is waar embedded CI/CD fundamenteel anders is dan web. Unit tests op de host missen per definitie alles wat hardware-specifiek is: UART-timing, WiFi-reconnectie, flash-write snelheid, heap-fragmentatie onder load. Hardware-in-the-Loop (HIL) tests vullen dat gat.
De opstelling is een self-hosted GitHub Actions runner (een Ubuntu server) met de target-hardware via USB aangesloten. Docker-containers leveren de testinfrastructuur (MQTT-broker, HTTP-server). De tests draaien als gewone pytest-tests die commando's sturen via seriële poorten en WebSocket, en asserten op het gedrag van de echte firmware.

hil:
runs-on: [self-hosted, linux, hil]
timeout-minutes: 60
needs: [build-esp32, build-stm32]
steps:
- name: Start supporting services
run: docker compose up -d mosquitto fw-server
- name: Flash STM32
run: hil/scripts/flash_stm32.sh hil-artifacts/stm32/sensor_node.bin
- name: Flash ESP32
run: hil/scripts/flash_esp32.sh hil-artifacts/esp32/iot_gateway-merged.bin
- name: Run HIL tests
run: python3 -m pytest tests/ -v --timeout=60
De flow: builds draaien parallel op GitHub-hosted runners (die hebben de toolchains), artifacts worden gedownload op de self-hosted runner, devices worden geflasht, tests draaien. Na afloop worden JUnit XML-resultaten en logs als artifact geüpload.
Concurrency is kritisch. Er is maar één set hardware. Twee parallelle runs zouden elkaars devices flashen. De concurrency-group lost dit op:
concurrency:
group: hil-hardware
cancel-in-progress: false
Let op: cancel-in-progress: false. Bij de reguliere CI-workflows is true logisch: een nieuwe push maakt de oude overbodig. Maar bij hardwaretests wil je de lopende run laten afmaken. Het halverwege afbreken van een flash-operatie kan het device in een ongedefinieerde toestand achterlaten.
- Boot-sequentie: WiFi verbindt, MQTT verbindt, STM32-protocol wordt operationeel
- Protocol: commando's worden correct verwerkt, sequentienummers kloppen, ongeldige commando's worden afgewezen
- Sensordata: temperatuurwaarden binnen fysiek plausibele grenzen, timestamps monotoon oplopend
- Dashboard: meerdere WebSocket-clients ontvangen broadcast, client-limiet wordt gerespecteerd
- OTA: firmware downloaden, flashen, rebooten, en verifiëren dat het device weer operationeel is. Inclusief afwijzen van firmware met een ongeldige RSA-handtekening
De totale doorlooptijd is 5–15 minuten, afhankelijk van of de OTA-tests draaien.
Laag 6: Security scanning, secrets detecteren
Eén per ongeluk gecommitte AWS-key of WiFi-wachtwoord kan een heel systeem compromitteren. In embedded projecten is het risico groter dan gemiddeld: credentials worden vaak hardcoded in header-bestanden, en private keys voor firmware-signing staan soms in dezelfde repository als de firmware.
Gitleaks scant elke push en elke PR op patronen die lijken op secrets: AWS keys, private keys, API-tokens, wachtwoorden:
- name: Scan for secrets
run: |
gitleaks detect \
--config .gitleaks.toml \
--source . \
--log-opts "$LOG_OPTS" \
--redact \
--exit-code 1
Twee details die het werkbaar maken:
De --log-opts parameter beperkt de scan tot de commits in de huidige push of PR. Een full-repo scan bij elke push is te traag en geeft ruis van historische commits. Door alleen de nieuwe commits te scannen, is de feedback loop kort en de output relevant.
Het .gitleaks.toml configuratiebestand bevat allowlists voor bekende false positives: RSA public keys (die zijn per definitie publiek), firmware checksums die op keys lijken, en test-credentials in documentatie. Zonder deze allowlist zou Gitleaks bij elke PR klagen over de embedded public key.
Laag 7: Release, van tag tot device
De release-pipeline triggert wanneer een version tag (v*.*.*) wordt gepusht.
De release-flow heeft drie stappen: build, sign, publish.
Build is identiek aan de reguliere CI, maar zonder test-credentials. Release-firmware gebruikt de productie-configuratie. Sign is de kritische stap. Elke binary wordt gesigneerd met een RSA private key die alleen als GitHub Secret bestaat. De key wordt tijdelijk naar disk geschreven, gebruikt voor het signen, en daarna onmiddellijk gewist:
- name: Write signing keys from secrets
run: |
echo "${{ secrets.ESP32_OTA_SIGNING_KEY }}" > ESP32/keys/ota_signing_key.pem
echo "${{ secrets.STM32_PRIVATE_KEY }}" > ESP32/keys/stm32_private_key.pem
- name: Upload firmware to AWS S3
run: python3 tools/upload_firmware.py artifacts/esp32/iot_gateway.bin ...
- name: Shred private keys
if: always()
run: shred -u ESP32/keys/ota_signing_key.pem ESP32/keys/stm32_private_key.pem
Het if: always() op de shred-stap is essentieel: zelfs als de upload faalt, worden de keys gewist. De keys mogen nooit op disk achterblijven na een CI-run.
production). Dit voorkomt dat een per ongeluk gepushte tag onmiddellijk een release triggert. Iemand moet bewust op "approve" klikken voordat de signing keys worden ontsleuteld.
sign-and-release:
environment: production # Requires manual approval
needs: [build-esp32, build-stm32]
Path filtering en concurrency
Path filtering voorkomt dat irrelevante wijzigingen pipelines triggeren. Een documentatie-wijziging triggert geen STM32-build. Een wijziging in de ESP32-code triggert geen STM32-pipeline. Dit bespaart CI-minuten en houdt de feedback loop kort:
on:
push:
paths:
- "ESP32/**"
- "common/**"
- "scripts/lint.sh"
- ".github/workflows/esp32-ci.yml"
Merk op dat common/** in zowel de ESP32- als de STM32-pipeline staat. Gedeelde code wordt op beide platformen gevalideerd.
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: true
Dit is een subtiliteit die in de praktijk veel CI-minuten bespaart. Zonder concurrency control bouwt elke push een wachtrij op. Met cancel-in-progress draait alleen de meest recente commit, wat bijna altijd is wat je wilt.
Caching-strategie: de verborgen tijdbesparing
In embedded CI kan caching het verschil zijn tussen een pipeline van 15 minuten en een van 3 minuten. Drie dingen worden gecachet:
| Wat | Key | Besparing |
|---|---|---|
| ARM GCC toolchain (500 MB) | Vaste versie-string | ~60 s download vermeden |
| ESP-IDF toolchain (1,5 GB) | Docker image + sdkconfig hash | ~120 s setup vermeden |
| Ccache compiler cache | SHA-based met fallback | 5–10 min op incrementele builds |
De ccache-strategie verdient uitleg. De key is ccache-{platform}-{sha}, met een restore-key van ccache-{platform}-. Dit betekent:
- Bij een exacte SHA-match: volledige cache hit (zeldzaam, alleen bij re-runs)
- Bij een prefix-match: de meest recente cache wordt geladen, en ccache bepaalt zelf welke objecten nog geldig zijn
Het resultaat: een incrementele build na een kleine wijziging hercompileert alleen de geraakte bestanden. De rest komt uit de cache.
Multi-platform: de gedeelde-code uitdaging
Een dual-microcontroller platform heeft een unieke uitdaging: code die op beide platformen draait. De common/ directory bevat gedeelde headers, protocoldefinities, en utility-functies. Een wijziging hier moet op beide platformen gevalideerd worden.
De aanpak is drie parallelle workflows:
- ESP32 CI bouwt en analyseert ESP32-specifieke + common code
- STM32 CI bouwt en analyseert STM32-specifieke + common code
- Unit Tests test common code op de host (x86-64)
Elk van deze workflows triggert op wijzigingen in common/**. Een bug in een gedeelde header wordt dus op drie plekken tegelijk gevangen: de ESP32 compiler, de ARM compiler, en de host compiler. Elk met hun eigen warnings en interpretaties van de C-standaard.
Waar te beginnen
Je hoeft niet met zeven lagen te beginnen. Begin met bouwen: één workflow die compileert en de binary-grootte valideert. Dat alleen al voorkomt de meest voorkomende problemen. Voeg static analysis toe zodra de build stabiel is. Bouw unit tests op voor de code die je het vaakst aanraakt.
HIL-tests zijn de grootste investering, maar ook de grootste multiplier. Ze zijn pas urgent zodra je twee keer een bug hebt gevangen die alleen op hardware reproduceerbaar was. Dat moment komt sneller dan je denkt.
De release-pipeline met signing is pas noodzakelijk wanneer je firmware naar devices in het veld stuurt. Maar als dat moment aanbreekt, is het geen luxe meer.
Zodra de pipeline de eerste paar bugs voorkomt heeft hij zichzelf teruggewonnen. Elke volgende bug is pure winst.
Wil je een CI/CD pipeline opzetten voor jouw embedded product?
Van cross-compilatie tot gesigneerde releases, ik help je met een pipeline die past bij jouw platform, toolchain, en deployment-strategie.
More Articles
Hoe pas je OT-veilig OTA updates toe op STM32 en ESP32?
Zo bouw je een OTA-systeem dat firmware veilig en betrouwbaar naar devices in het veld brengt, met werkende code en conc...
The Jevons Paradox of Software Engineering
AI writes code faster than I do. For some things, it writes better code than I do, and after all the work I've put into ...